Dla czarnego hakera znalezienie nieznanej wcześniej podatności w jądrze Linuksa jest jak rozbicie banku. Nagle stoją przed nim otworem potencjalnie miliony serwerów i systemów sterujących urządzeniami, a w większości przypadków będzie można na nich uzyskać przywileje roota. Użytkownicy zdecydowanie nie chcą takiego scenariusza, więc twórcy jądra starają się temu zapobiegać.
Czysto teoretycznie ścisłe standardy pisania kodu oraz zaawansowany system zarządzania jakością oprogramowania powinny umożliwić natychmiastowe wyłapywanie dziur i eliminowanie ich przed wydaniem programu. Pod tym względem świeci przykładem OpenBSD, który przez 20 lat miał tylko dwa przypadki złamania zabezpieczeń [1]. Zdecydowanie przychylam się do procedur ostrożności stosowanych przy OpenBSD, ale bądźmy realistami: jądro Linuksa to niebotyczne sterty kodu, którego nikt nie jest w stanie sprawdzić wystarczająco dogłębnie. Z zależnościami bywa różnie, a więc różnią się także możliwe kierunki ataku (dokładna ilustracja problemu w ramce „Niepozorny początek”).
Złożoność jądra Linuksa ma swoje konsekwencje – duże prawdopodobieństwo obciążenia starym kodem i błędy tkwiące w środku od niepamiętnych czasów. Pod koniec 2010 r. [4] Jonathan Corbet sprawdził, ile czasu minęło od powstania błędów związanych z bezpieczeństwem do ich wykrycia właśnie w tamtym roku – 22 na 80 podatności siedziało w kodzie przez ponad pięć lat!
Z praktycznych doświadczeń przy pracy z jądrem wyłoniło się podejście, które jednocześnie utrudnia ataki i ogranicza skutki wykorzystania słabych partii kodu. Taka walka na dwóch frontach jest celem projektu Kernel Self-Protection [5].
Włamy dla każdego
Gdy bliżej przyjrzeć się atakom i wystarczająco uwzględnić ich historię, widać, że większość programów służących do atakowania wykorzystuje ten sam schemat. Atakujący próbuje dopisać nowy kod programu do działającego już procesu, aby tenże proces wykonał obcy kod ze swoimi własnymi uprawnieniami. Przy atakach na jądro dorzucane w ten sposób bywają polecenia SQL, polecenia powłoki lub (najczęściej) kod binarny. Do wstrzyknięcia kodu atakujący wykorzystuje błędy programowania pozwalające podejrzeć zawartość pamięci i manipulować licznikiem programu.
Licznik programu to rejestr procesora wskazujący na kolejną instrukcję do wykonania. Programy 16-bitowe na procesory Intela miały wskaźnik instrukcji (IP), świat 32-bitowy posługiwał się Extended IP (EIP), przy 64 bitach zaś jest to Relative Instruction Pointer o mrocznym skrócie RIP. Niemal wszystkie ataki zmierzają do przeinaczenia zawartości tego rejestru tak, by wskazywał na jedno z poleceń atakującego, a nie kolejne polecenie zamierzone przez programistę.
Bezpośredni dostęp do tego rejestru z prawami zapisu jest praktycznie niemożliwy, więc stosuje się mały wybieg. Gdy program wywołuje funkcję, to kopiuje do stosu jej adres powrotu (czyli miejsce, w którym wznowi działanie po wykonaniu funkcji). Ponieważ w stosie trzymane są zmienne lokalne dla funkcji, którymi można manipulować na wejściu, adres powrotu jest popularnym celem ataków.
Niepozorny początek
Niektóre możliwości złamania zabezpieczeń pozostają dobrze ukryte. Podatność CVE-2015-7547 z początku była pozornie nieszkodliwym błędem zgłoszonym w Glibc 2.20 [2]. Błąd, istniejący prawdopodobnie od Glibc 2.9, powodował krytyczne zakończenie programu. Pół roku później okazało się, że pomysłowa kombinacja uprawnień dostępu umożliwia atak na bazie tego błędu.
Programiści Glibc przewidzieli w stosie bufor o rozmiarze 2048 bajtów na odpowiedź DNS, która miała trafiać na stertę, jeśli była większa od tego limitu. Ale czasem operacja nie udawała się, ponieważ funkcja odpytywała adres IPv4 lub IPv6, a przy drugiej odpowiedzi próbowała zużyć resztę miejsca w buforze. Zapytanie do sterty o większy bufor następowało dopiero wtedy, gdy ta druga czynność kończyła się niepowodzeniem. Zmienna przechowująca wskaźnik na bufor nie była jednak aktualizowana, więc dostęp do stosu nadal był otwarty. Sprawdzanie rozmiaru stosu nie pasowało już do sytuacji, co umożliwiało przepełnienie stosu.
Wykorzystanie tego błędu (już unieszkodliwionego) nieco jednak komplikuje życie atakującemu – konieczne jest wysyłanie pakietów DNS większych niż 2 kB. Zdaniem osób zgłębiających podatność atakujący musiałby więc przejąć kontrolę nad jakimś serwerem DNS lub przynajmniej fałszować pakiety DNS metodą man in the middle [3]. Ten atak wymaga też idealnego wyczucia czasu – druga odpowiedź musi pojawić się po wyczerpaniu limitu czasu, a pierwsza ma być większa niż 2 kB. Przy drugiej odpowiedzi Glibc nieprawidłowo ustawiłby rozmiar bufora na większy, a tak naprawdę przypisałby do stosu ten mały, co umożliwia przepełnienie stosu.
Atak jest trudny do wykrycia właśnie ze względu na nietypową kombinację parametrów i złożone zależności. Jednym ze sposobów wykrywania tego typu ataków są kanarki (o których za chwilę). Jeśli sprawdzona wartość kanarka nagle się różni, oznacza to przepełnienie bufora. Kolejny sposób to randomizacja rozkładu przestrzeni adresowej. Stos niedający się wykonać znacznie utrudniłby atak, a tym samym zmniejszył ryzyko.
Obrót w ruinę
Jest kilka sposobów podmiany adresu powrotu. Przepełnienie bufora jest dość brutalne – atakujący zwyczajnie przepełnia zmienną dużą ilością danych i zasypuje adres powrotu (Rysunek 1). Subtelniejsza metoda ataku bazuje na podatnościach łańcucha formatującego, które dają możliwość odczytu i zapisu w pamięci w celu manipulacji stosem.
Kolejną możliwością jest przepełnianie liczb całkowitych – atakujący może na przykład wykorzystać fakt, że liczby całkowite ze znakiem i bez znaku mają różne zakresy wartości. Liczbę 128 bez znaku można zmienić w –128. Jeśli program sprawdza tylko zgodność takiej liczby z jakimś górnym pułapem (bo na przykład stos trzyma maksymalnie 100 wartości), to –28 od strony technicznej jest odpowiednie. Teraz liczba, zamiast zajmować przewidziane przez programistę obszary pamięci od 0 do 100, rozciąga się od –128 do 100, co może wywołać przepełnienie.
Ratuj się kto może
Atakujący może próbować manipulować stosem lub stertą. Obie struktury to obszary zapisu zwykle przechowujące jakieś dane, stąd popularną strategią, zalecaną również przez Kernel Self-Protection, jest oznaczanie obszarów pamięci jako wykonywalnych lub niewykonywalnych (czyli deklarowanie ich jako kodu lub danych). Nowsze procesory mają przeznaczony do tego celu bit w deskryptorze strony. W terminologii AMD ten bit nazywa się No Execute (NC), a w Intelu – Execute Disable (XD). Jądro Linuksa wspiera stosowaną w tym kontekście ochronę przez zapisem.
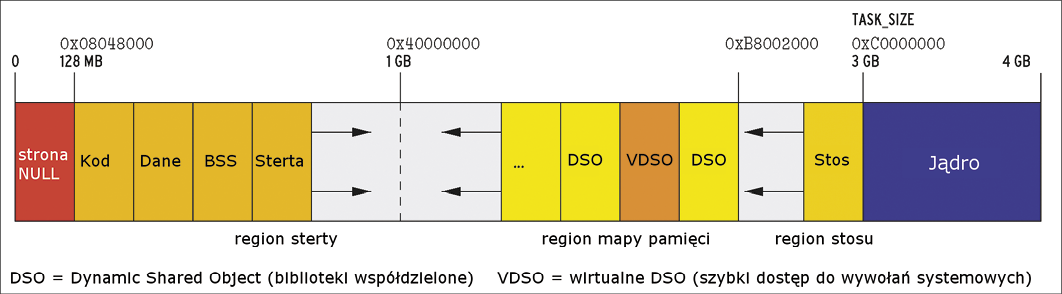
Rysunek 1: Jeśli w wyniku ataku uda się zapisać w buforze stosu więcej danych niż przewidział programista, to atakujący, przepełniając bufor, może nadpisać prawidłowy adres powrotu.
Takie prawa dostępu nie dają stuprocentowej ochrony przed atakami, ale przynajmniej je utrudniają. Zaawansowany haker nadal może zyskać kontrolę nad systemem za pomocą ataku Return to Libc, w którym dochodzi do zapisania w stosie adresu wejściowego funkcji execve() wraz z odpowiednimi parametrami [6] [7].
Po udanym ataku haker może w pierwszej kolejności wpłynąć tylko na zawartość pamięci należącej do złamanego procesu. Na szczęście współczesne procesory oddzielają pamięć jądra od pamięci aplikacji – w tym przypadku funkcja jądra nie ma prawa wykonywać żadnych poleceń, które zostały wstrzyknięte do przestrzeni użytkownika. Taka ochrona sprawia, że atak przedstawionym sposobem jest trudniejszy.
Kanarek kontra wyciek
Przepełnienie stosu powoduje jego częściowe nadpisanie. Można się przed tym bronić, stosując tzw. „kanarka”, niemożliwą do odgadnięcia przez atakującego sekwencję bitów występującą przed adresem powrotu. Jeśli przy powrocie do funkcji wzorzec kanarka nie pasuje, jest to ostrzeżenie, że ktoś nadpisał stos. Nazwa mechanizmu pochodzi od kanarków, których zachowanie ostrzegało górników przed niebezpiecznym stężeniem gazów.
Wprawny włamywacz jest w stanie ominąć zabezpieczenie kanarkiem. Istnieje na przykład technika zwana trampoliną, w której nagina się położenie wskaźników w programie tak, by wskazywały na adres powrotu. Taki zabieg wymaga jednak większego wysiłku i skorzystania z już odkrytych podatnych wskaźników. Atakujący może też próbować odczytać wartość kanarka i odpowiednio dopasować przepełnienie bufora. Temu drugiemu fortelowi programista może zapobiec, randomizując wartości kanarka.
Podobną linią obrony są stosy-cienie (shadow stacks) – przechowują one kopię adresu powrotu bardzo trudno dostępną dla atakującego. Zanim proces zwróci adres w pamięci, sprawdza, czy kopia pasuje do oryginału [8].
Oprócz stosu również sterta bywa podatna na przepełnienie. Włamywacz często korzysta z błędów typu „użycie po zwolnieniu” – programista zwalnia pamięć funkcją free(), ale później znowu korzysta z tego samego wskaźnika. Takie błędy można poprawić bardziej rygorystycznie, pilnując dostępu do stref pamięci w jądrze.
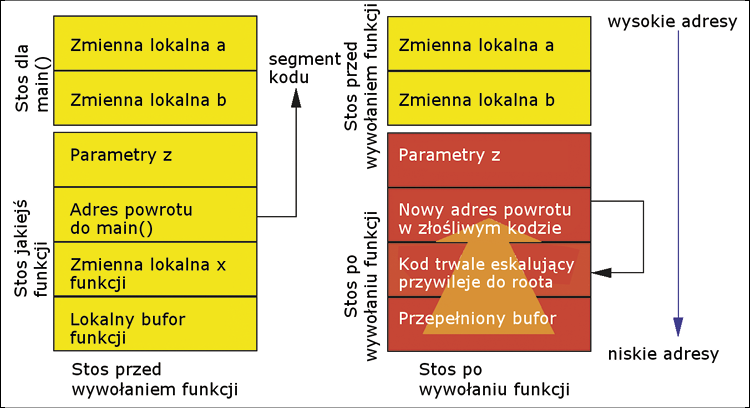
Rysunek 2: W architekturze i-386 rozkład przestrzeni adresowej zwykle określony jest na 32-bitowym układzie. W miarę dynamicznego zwiększania się rozmiarów sterty i stosu zbliżają się one do siebie.
Kupon na loterii
Włamywacze wstrzykują kod, bazując na powszechnie dostępnej wiedzy o rozkładzie pamięci systemu operacyjnego (Rysunek 2). Jeśli jądro stosuje losowy układ adresów w pamięci, atak na system jest jak gra hazardowa. Chociaż można próbować technik takich jak heap spraying (porozrzucanie kodu na całej stercie), to jednak koszt ataku w każdym przypadku wzrośnie. Jeśli zarówno samo jądro, jak i jego moduły ładowane są do losowych adresów i jeszcze w losowej kolejności, to takie moduły trudniej zaatakować. Losowe adresy bazowe stosu również zwiększają narzut potrzebny do udanego ataku.
Im bardziej powodzenie ataku zależy od szczęścia, tym bardziej włamywacz stara się zdobyć przypadkiem wystawione na zewnątrz informacje o strukturze pamięci lub wartościach kanarków. Atakującym sprzyja fakt, że pamięć zwolniona przez program nie jest nadpisywana. Przydają się także niezadeklarowane zmienne oraz podatności łańcuchów formatujących.
Aby nie pozwolić nikomu zebrać takich danych, należy nadpisywać pamięć zaraz po jej zwolnieniu. Dostęp do funkcji można natomiast uzyskiwać nie po ich adresach, lecz na podstawie ID i tabeli, analogicznie do tablicy wektorów przerwań. Taka zapobiegliwość sprawi, że adresy poza jądrem pozostaną nieznane i trudniejsze do przewidzenia przez atakujących.
Modułowość jest dobra
Włamywacze, którym mimo wszelkich środków obrony udało się wstrzyknąć złośliwy kod, zwykle starają się w następnej kolejności zainstalować rootkita – przez zwyczajne załadowanie do systemu własnego modułu jądra. W ramach obrony administrator systemu może skompilować jądro statycznie – bez obsługi modułów, ale w zastosowaniach innych niż urządzenie sterujące takie jądro bywa niewygodne w użyciu. Członkowie projektu Self-Protection proponują, aby możliwość ładowania modułów miało tylko kilku zalogowanych lokalnie użytkowników.
Wnioski
Idę o zakład, że w jądrze Linuksa czai się jeszcze wiele innych problemów niewymienionych w spisie podatności i zagrożeń (CVE). Projekt Kernel Self-Protection ma na celu opracowanie funkcji uszczelniających jądro, na przykład randomizację rozkładu przestrzeni, aby trudniej było się włamać, a w razie udanego ataku – szkody były mniejsze.
Przy stosowaniu praktyk bezpiecznego programowania nie wolno, robiąc jedno – zapominać o drugim. Ukierunkowane przeglądy kodu i skoncentrowane zarządzanie jakością powinny być nieodzowną częścią każdego projektu programistycznego.
Autor
Tobias Eggendorfer jest profesorem bezpieczeństwa IT w Hochschule Ravensburg-Weingarten i niezależnym konsultantem informatycznym (http://www.eggendorfer.info).
Info
[1] Strona o bezpieczeństwie OpenBSD: https://www.openbsd.org/security.html
[2] „In send_dg, the recvfrom function is NOT always using the buffer size of a newly created buffer,” CVE-2015-7547: https://sourceware.org/bugzilla/show_bug.cgi?id=18665
[3] Łata do CVE-2015-7547: https://www.sourceware.org/ml/libc-alpha/2016-02/msg00416.html
[4] Corbet, Jonathan. „Kernel vulnerabilities: old or new?”: https://lwn.net/Articles/410606/
[5] Kernel Self-Protection: https://www.kernel.org/doc/html/latest/security/self-protection.html
[6] The GNU C Library Reference Manual, “Executing a File”: https://www.gnu.org/software/libc/manual/html_node/Executing-a-File.html
[7] C0ntex. „Bypassing non-executable-stack during exploitation using return-to-libc”: http://infosecwriters.com/text_resources/pdf/return-to-libc.pdf
[8] Dang, Maniatis, and Wagner. „The Performance Cost of Shadow Stacks and Stack Canaries”: https://people.eecs.berkeley.edu/~daw/papers/shadow-asiaccs15.pdf





